When I made the switch from finance to software development, I was doing mostly scripting on small projects, nothing major. Since I started the job, I learned a bunch of very valuable lessons. I didn’t have a Computer Science degree, just a passion to tinker and invent things. Many of the below discoveries might be obvious to many, but for people trying to do a similar move, it will definitely shorten your learning curve or at least get you prepared a little more for what’s to come.
Agile vs Kanban vs XP
Usually when it comes to software development methodology, the “Church of Agile” is strong with many. Some do Kanban, I haven’t seen anyone do Extreme Programming. I’ve recently finished the “Extreme Programming Pocket Guide” by O’Reilly. It is the earliest framework of the three and it feels like Scrum v0.5 with a lot of ideas that are already deeply embedded in Scrum. An example – “You are not gonna need it”, reflecting project scopes and requirements change frequently. I will not go into what each of them represent, that’s not the goal of this post.
My discovery is that nobody does pure Agile, everyone modifies it to make it fit their workflow and team dynamic and adopts only parts of it. I attended something like 4-5 lectures on Agile and Kanban, and all lecturers agreed on the above. I endorse this wholeheartedly as well, as I don’t believe in the one framework fits all approach. The other valuable lesson I gathered is project management is a beast. If you don’t tame it in the beginning, it gets wild no matter what approach you pick. The aforementioned frameworks are not to have good estimates of delivery to Product Managers, as they are often promoted, rather frameworks to avoid chaos in the production process and keep stakeholders alerted. The reason I believe this is that no 2 sprints are the same and an identical delivery level is harder to achieve in real-life than on paper. I don’t know of a team who has perfect team velocity, exact delivery, etc. The amount of variables is too big. You will always encounter issues you didn’t expect. Sometimes the scope of a bugfix will be much greater than estimated. This is still why software engeering is still the industry with the worst time estimations. The real world doesn’t boil down to story points and 2-week sprints, even if you reach the point of perfect estimation – people on holidays, speed of coding based on skillset, etc. The cost of estimation I believe will outweight the efficiency brough by the framework, which in it’s core is simplification and streamlining the process (according to the 12 principle Manifesto).
Having spoken with much more experienced developers (>12 years of professional coding) asking them how they did things before the current times where everything is a buzzword. The main difference from my understanding is the continuous delivery part. Which I think was made possible mainly by the progress of server-side technologies and allowing frequent releases without client action, rather than hoping people will install an update. Everyone was given a project they work on for say 6 months, nobody knew what the other guy was doing or how he was doing it. All that mattered was that at the end of the 6 months when everything was expected to fit together it actually worked, and it did, but the result was like the below image:

Continuous delivery,I believe, is the biggest step forward in the development mindset. As a person who mostly scripted stuff alone, I never gave it a second thought on how a development team coordinates effort and splits tasks in a corporate environment on a large and very distributed scale. I always did all the tasks. Estimation of effort was always easy, I knew my skillset, coding speed, free time, my own estimates have always been pretty on point. Never before did I use JIRA, Trello or Pivot Tracker. But with multiple people working at difference pace, I discovered that
Task estimates are tough
The simplest example is a novice team joiner vs. the original creator of the system, who knows every corner of the code. Ask them to estimate the same task, you will get 2 wildly different estimates. You average it, put the story points. If the expert takes the task, you’ve overestimated, if the novice takes, you underestimated. Yet, anyone should be able to pick any one task, as otherwise could create the systematic problem making someone indispensible, which is not good. When something breaks, everyone is in big trouble. As the novice gains experience the estimates should converge, but it rarely happens. Why? A few possible reasons are some people like to have a margin of error, as they don’t know where the dragons are others are overconfident in their ability. The short answer – psychology plays an important role. You have techniques like Assessing the accuracy of estimates = |Actual Effort – Estimated Effort| / Actual Effort, but then the above problem still stands. I haven’t done extensive research on the topic, but I find it interesting nobody has found a proper solution to such a pervasive problem.
Version Control
Coming from a web design background, my version control was multiple timestamped copies of the same folder with scripts, images, etc.
This is also the time I was impressed by Microsoft Word’s track changes feature. After becoming a proper developer, things definitely took a turn. Never before had I used Git or SVN. Git is the current one to rule them all with different providers like GitHub, GitLab, BitBucket and others. It did gain popularity with the release of GitHub because of its user friendly ability to manage repositories globally. With that said, the learning curve isn’t small, but it’s not huge either, after all it’s a tool from developers for developers, which translates to “You get a CLI (Command-line interface) and that’s it.” Once you memorize the 10-12 commands and a few command tails to use proficiently you are set. There are many GUI tools, including an official one, but I haven’t seen a single person use one. The effort required to perform the same tasks outweights massively the command line interface. The only thing I used UI for is the file differences, but my text editor of choice – Visual Studio Code has absolutely nailed this feature for me and for anything smaller, VIM is more than enough. I became such a fan of Git and GitHub in particular that was also kind of what sparked the start of this blog (2nd and 3rd post published), I even attended a session on contributing to the project in an open source event. Once you master the Git lingo – Merge, Rebase, Branches and all that. The true appreciation of the system comes when you start deploying software and you have to do a hot-fix or have to change implementation approach. Branches and other functionality will all fit into place and then you’d wonder how the world deployed software before that.
Coding is easy, Design is hard
When it comes to coding, you need to have the fundamentals absolutely nailed. If you start construction on shaky fundamentals, you’ll have to rebuild it multiple times. This actually applies to life in general, not just programming. In the beginning you care about getting stuff to work. So the emphasis is on quick and hacky, as long as it works, it’s fine. That’s the mindset that takes a massive hit when you start coding professionally. As time passes you start to know better what’s happening and having working stuff gets lower in the priorities. The focus gradually shifts to design and how extensible and maintanable is what you are building. Beware of becoming one of the people that have an excellently designed application that never works. Being a perfectionst doesn’t pay off. You can strive towards perfection, but you cannot ever achieve it. It’s a great time to pick up a book on design patterns, so that you can know an anti-pattern like “Singleton” and “Factory Method” design pattern for example and when to use which and when to avoid them.
The Const keyword
When I wrote Jupyter Notebooks in Python or C# applications I never used the word CONST. Like ever. It does have two consequences – human one being readability, machine one being optimization. No other word describes the intention of “Do not touch” like Const does (only exception being an angry all capitals comment 🙂). It’s one of these tools that you don’t really appreciate until you see used, if you need to read a brand new codebase of a few hundered thousand lines, nothing speeds up things like seeing Const – ok, this is it, and never changes, moving on. When you troubleshoot, you can immediately focus on the stuff that change state or modify, so automatically all const variables drop in importance. I was told about it and how crucial it is, as it is when the compiler optimizes these variables to remove dead code paths, etc. However the real value for me is truly readability. It’s one of the things you need to try and then it just clicks. Building the habit of using it was painful. My initial code reviews were literred with “Why not use const?”, but eventually I got there.
Developers don’t get UX
If you’ve ever used a linux distribution before the creation of Ubuntu, you know what I mean. There’s a reason why the original Ubuntu motto was “Linux for Human Beings”, as if Linux users during those times were a different species. There was a joke when Angry Birds was quite popular, if linux developers created Angry Birds, it will be a command line game with “launch bird -30 degrees”. Whoever came up with this joke was on the mark. Coming from a client-facing background, part of my job was teaching people how to use a piece of functionality, I put an enourmous value on user experience, not just the interface. Most developers never see the end user of the product, so they never appreciate a tiny 1 line change in code could save a client 2 minutes a day and make him a much happier and satisfied customer. Clients don’t have same the power over the product, the way developers can customize their command shell or shortcuts for their favorite text editor as in most cases it’s not open source. One of my favorite principles is “POLA” Principle of least astonishment, everything should behave, the way the client expects it to. Eg. A hamburger menu icon in an Android application should open the menu and not do anything else. It’s harder than it sounds, as people expect different behaviours. One of my favorite problems I like to pose myself is how to reduce the amount of settings to a minimum for everything we add, otherwise we end up in the following situation:
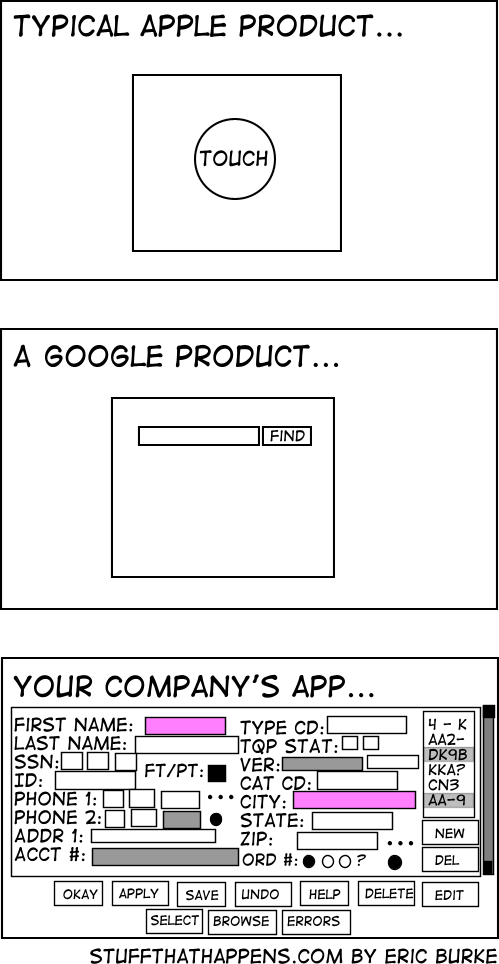
Design the User Interface first, then design what the backend should send forward
A paradigm that I’m a strong believer in is UI first, back-end second. Not in order of importance, but in order of design. Once you have the idea on how things should look like, a mere mock up is sufficient, suddenly the output of the backend becomes clear and you abstract away the UI having any business logic inside. It merely becomes a vessel of nice data presentation. If you go the other way around, either the UI ends up hideous as the back-end sends the data in a format that was not as intendend so you have to do plenty of transformation on the front end and you end up with tiny bit of business logic in there, that’s more of an eye-sore than anything else. The better alternative being having a very flexible back-end that can produce any output to fit the UI, that would be great, but the cost of building it and maintaining will far outweight the benefit if you just started in reverse. Obviously, this is not a one solution fits all, but even for infrastructure teams, that provide APIs, they start with what the APIs should look like and build backwards. The cost of trying it out is not big, you might find it helpful.
Testing & Error Handling
When I wrote simple scripts, my testing was a pure trial and error, I never used gTest and gMock before. However, being a diligent developer means you assume the worst and manual trial and error can only get you so far. You have to assume that nobody sanitizes inputs (prevent people from executing commands from simple entry fields). You cannot trust the other guy to do the right thing and throw an exception for example. If you want a resilient distributed system you have to be a bit paranoid in the development process.
The only downside is that your testing is as good as the tests you write, if you never tested for a perfect storm of failures, you have failed at testing. The problem is often you test for what you’ve written the code to do, but don’t think of test cases you didn’t think of when implementing the function. Hope that makes sense.
Setting up testing is painful, most of the time it requires a specific paradigm of design in order to make something testable. In C++ for example, you need to do interfaces and mock classes to use gMock. In UI, you can’t nesserily test everything. If you are not using a popular framework like Angular or React, you might have to build one yourself for your product.
Many people hate on TDD (Test Driven Development) and in the beginning I can see why. The cost of creating the first test is too high, but after you start adding features to a large scale system, what better method do you have to offer a guarantee you haven’t broken something old by refactoring a tiny corner of the codebase. The only way I have discovered up to this moment to make sure you are not building a house of cards is tests and plenty of them. You might have to update them when introducing new features, still it’s a time better spent than 3 days reading logs to figure out what’s causing a failure at the other end of the system that you haven’t touched.
The programming language is not as important
There’s a joke that goes: “If you have a problem to solve and you choose Perl, you now have 2 problems”. In real life, people start with the language they are most comfortable with. That’s understandable, but it might not be the case that language is the best suited to solving the problem. Picking a safety language is problem, there’s a reason why we have so many of them. When I was in finance, I believed that proper developers are only those that do C++ or C. JavaScript and Python can be done by anyone. The closer to the metal you are, the better developer you are. After 2 years, I now do more TypeScript and Lua than C++, both of which are scripting languages but allow for navigating plenty of business logic.
The problem with picking the wrong the language is that you take that language’s mindset with you. You end up coding with a language, rather than coding into a language. Let me give you an example: If you’ve done 5 years of C++, you end up using object-oriented practices in a functional language and you end making hacks to make it look more C++-like rather than embrace the new language mindset. There might be instances where the language pick is not your call. Then you adapt to best of your ability. End of story.
Infrastructure is your biggest limitation
That one is more than obvious and it’s becoming less relevant by the minute as cloud infrastructure is eating the world at the moment. If you have a relational database provided, but you need to stream data fast and you are not offered anything better, like a no-SQL database, that’s a massive roadblock. Can’t use modern C++ as you need to support a compiler that was built in the previous century? All perfectly real problems, going away one step at a time, thanks to AWS, Google Cloud and Azure. If anything that’s an enourmous incentive to migrate software to 21st century and play with the latest toys.
You never know if your design is the right one, only time will tell
When you design something, making it as extensible as possible, you believe this is the most elegant design for the problem as of that moment. This might be true, however, in reality nobody knows if this is true, only time will tell. You can make the best assumptions as of right now and the current specifications, but you cannot predict the future. You can only stack the odds in your favour. Strong knowledge of design patterns will definitely pay off, so you start off with a good list of building blocks. The only sure element of the design you need to have is modularity, to easily replace things back and forth if it turns out one of the subsystems needs to be rethought entirely. Most modern language kind of enforce this – Node Package Manager and modern JavaScript. C and C++ already had this with the inclusion of header files. Many new frameworks enforce the bear minimum of proper development.
As this post became much longer than I intended, I’ll cut it here and write a part II later on.



0 Comments